
Building a Streaming Platform in Go for Postgres

At PeerDB, our mission is to create a Postgres-first data-movement platform that makes it fast and simple to stream data from Postgres to Data Warehouses, Queues and Storage. Our engineering focus revolves around 10x faster data movement, cost-efficiency, and hardware optimization.
In this blog post, we'll dive into our recent transition from a pull-and-push model to a more efficient streaming approach using Go channels. Let's explore why streaming is crucial and how this change significantly improved performance.
The Pull-and-Push Model
Before our recent change, we operated with a pull-and-push model. We fetched rows into an array in memory and then moved them to the target. While this approach worked well for smaller batch sizes, it presented issues with larger batches. Specifically, we couldn't parallelize the pushing while pulling, leading to a lack of pipeline efficiency. The split between pull and push time in a typical setup for us was 60-40.
This is how our code looked like before:
// sync all the records normally, then apply the schema delta after NormalizeFlow.
type RecordsWithTableSchemaDelta struct {
RecordBatch *RecordBatch // wrapper for "Records []Record"
TableSchemaDeltas []*protos.TableSchemaDelta
RelationMessageMapping RelationMessageMapping
}
Shifting to Streaming
Our new approach involves buffering and concurrently pushing data to the target (e.g., Snowflake) in batches, as we pull it from PostgreSQL. This pipelining of data transfer offers significant advantages:
Improved Efficiency: Pipelining allows us to overlap the pull and push phases, reducing overall processing time.
Reduced Latency: With pipelining, data reaches its destination more quickly, enhancing overall system responsiveness.
This is the shared structure after the change:
type CDCRecordStream struct {
// Records are a list of json objects.
records chan Record
// Schema changes from the slot
SchemaDeltas chan *protos.TableSchemaDelta
// Relation message mapping
RelationMessageMapping chan *RelationMessageMapping
// ... other fields
}
Harnessing Go Channels for Streaming
Go Channels are used to enable communication and synchronization between goroutines (concurrent functions) in a Go program. Channels allow one goroutine to send data to another goroutine and provide a safe way to exchange information. Here are a few benefits that Go channels provide:
Data Synchronization: Go channels provide granular control over data synchronization, preventing race conditions and ensuring data consistency as it flows through a system.
Resource Management: Go channels' blocking behavior at capacity prevents data overload, mitigating the risk of Out-of-Memory (OOM) errors and ensuring stability.
Concurrent Processing: Go channels enable efficient concurrent data processing, optimizing resource utilization and achieving high throughput across data retrieval, transformation, and insertion.
Error Handling: Built-in error handling mechanisms using select statements improve system robustness, allowing us to respond gracefully to exceptions and maintain reliability. Here goes our implementation of handling errors in Go channels
Synergy with Postgres Logical Replication: We use logical replication slots to manage CDC from Postgres. START_REPLICATION streams changes from Postgres at a given wal position into our buffer channels and waits until we ask for the next change. The back pressure mechanism provided by Go channels and the streaming capabilities of START_REPLICATION go hand in hand to ensure resiliency, by controlling memory utilization.
The Impact of Change
Our performance improvement is remarkable. In initial scale tests, we achieved:
Throughput: 10-12k Transactions Per Second (TPS)
Minimal Lag: 1-5 seconds
Compare this to our previous performance, which took roughly 30 seconds to complete similar tasks. The impact is undeniable, with our streaming model significantly outperforming the pull-and-push approach.
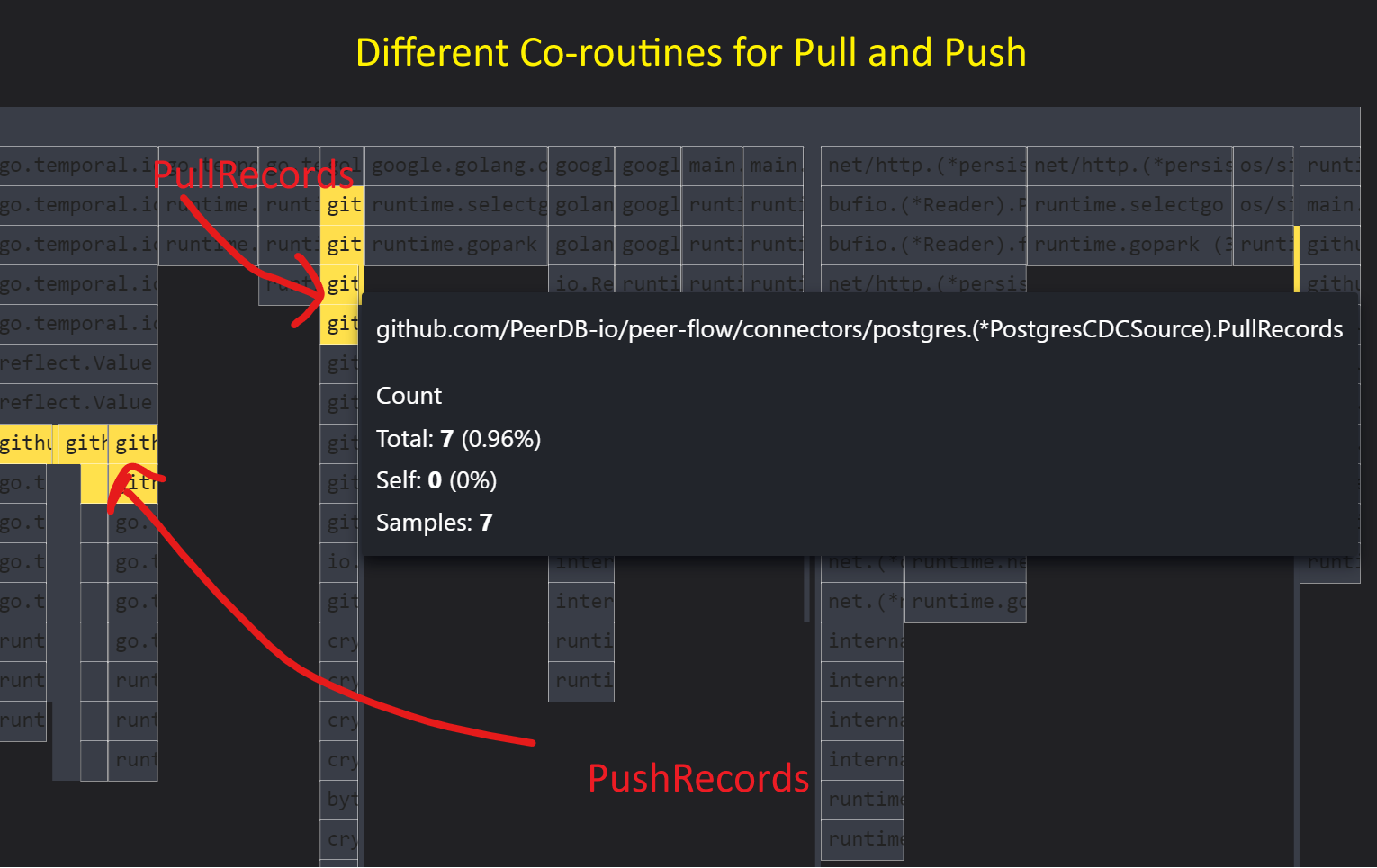
The above image shows the flame chart snapshot view of pulling records and pushing records occurring simultaneously.
Future Enhancements
Looking ahead, we are exploring additional optimizations to further enhance our system's resilience. One promising avenue is spilling the record stream to disk to prevent Out-of-Memory (OOM) issues. This approach would ensure that our system can handle even larger datasets without sacrificing performance or reliability.
Conclusion
In our pursuit of building a resilient data-movement platform for PostgreSQL, PeerDB has made a crucial shift from a pull-and-push model to an efficient streaming approach using Go channels. The results speak for themselves: improved performance, reduced latency, and a more responsive system.
As we continue to innovate and optimize, we aim to provide Postgres users with a data movement experience that is not only faster but also cost-effective and hardware-efficient. Stay tuned for more insights and updates as we push the boundaries of what's possible with PeerDB. If you want to give PeerDB a try for streaming data from Postgres and experience the above improvements, these links should prove useful: :)




