
Exploring versions of the Postgres logical replication protocol
Introduction
Logical Replication is one of the many ways a Postgres database can replicate data to other Postgres database (a.k.a standby). Logical replication directly reads from the write-ahead log (WAL), recording every database change, avoiding the need to intercept queries or periodically read the table. These changes are filtered, serialized and then sent to the standby servers where they can be applied. While logical replication is intended to be used by Postgres databases to send and receive changes, it also allows ETL tools like PeerDB to get a reliable stream of changes that can be processed as needed.
Logical replication started by only allowing streaming of committed transactions. It then evolved to support in-flight transactions followed by two-phase commits and then parallel apply of in-flight transactions. This blog will dive into this evolution, its impact on performance, and present some useful benchmarks. This blog is useful for anyone who uses Postgres Logical Replication in practice!
Components of logical replication
For a quick rundown, a full logical replication setup involves several crucial components. Please skip this section if you are already familiar with the concepts of logical replication.
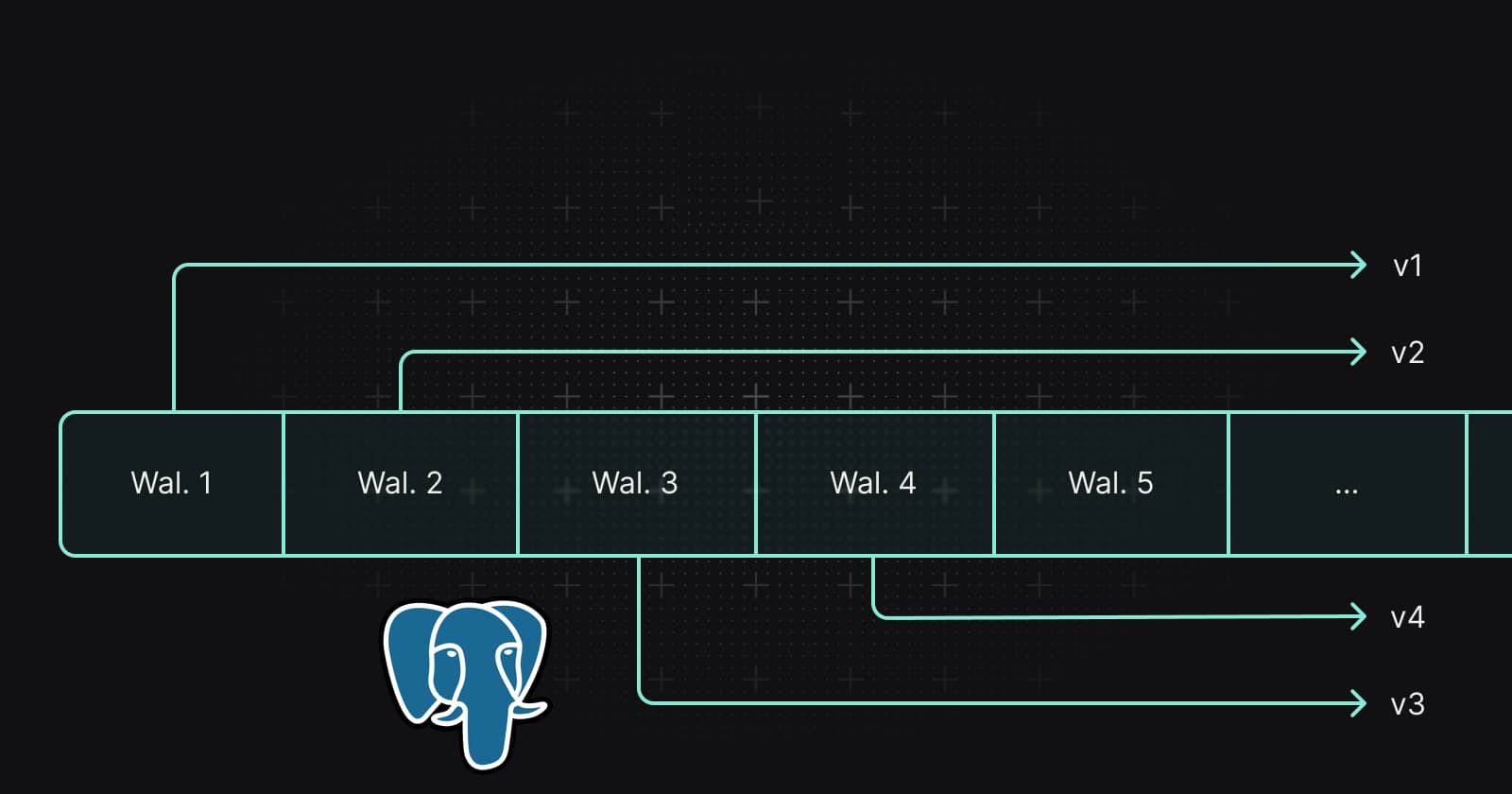
1. Replication Slot: A replication slot on the primary server is what reads changes from the WAL and passes it to the output plugin to be serialized and sent to the standby server (or ETL tool) to be applied. Periodically, the standby server sends a message to the primary to confirm that it has read the WAL to a certain point, at which point the slot can advance.
2. Publication: A publication is essentially a filter on the WAL changes. Publications are very powerful and can filter out schemas, tables and even particular columns of tables. You can also choose to publish inserts and not updates and also apply custom logic to filter out certain rows. When a standby starts reading from a replication slot, a set of publications are passed as input.
3. Subscriptions: A subscription is basically the Postgres syntax for creating a logical replication connection to a primary server for replicating changes from a slot and a set of publications. The standby then reads data from the primary and replicates it as long as the subscription is active. While this is Postgres specific, other tools end up behaving like subscribed standbys and get the same output from the primary server.
4. Output plugins: The replication slot passes raw WAL change data to an output plugin which serializes it to a stream of messages. This helps with the interoperability of logical replication as the message format is independent of the underlying database version or configuration. The de-facto output plugin is a Postgres project called pgoutput but other plugins like wal2json and decoderbufs enjoy support among the community.
Wait, logical replication has versions?
When starting logical replication (START_REPLICATION), there is a parameter called proto_version that allows users to opt in to newer semantics of the logical replication protocol. Starting with Postgres 14 in September 2021, three new proto_versions of logical replication have been added in consecutive releases. Looking at the docs for proto_version right now, we see this:
proto_version
Protocol version. Currently versions 1, 2, 3, and 4 are supported.
Version 2 is supported only for server version 14 and above,
and it allows streaming of large in-progress transactions.
Version 3 is supported only for server version 15 and above,
and it allows streaming of two-phase commits.
Version 4 is supported only for server version 16 and above, and it
allows streams of large in-progress transactions to be applied
in parallel.
While these all sound like good things, it's not clear for the average reader what they mean or what problems are being tackled. And for the informed reader who knows what these changes mean, it'd still be nice to understand how they are implemented and their impact on real-world workloads.
v1 - the status quo
To analyze the messages and semantics of the various protocol versions, we've written a small Go application called polorex. If you want to check out the code or try things out for yourself, check out the code in this repo.
To simulate a workload, we are running 2 transactions concurrently, inserting rows into the same table. The transactions insert rows in 100 batches of 250,000, totalling 50 million rows. The workload is simulated by a subcommand of the polorex application. The transactions are read and analyzed by another subcommand called txnreader which connects to the database and continuously reads the replication slot.
./polorex txnreader -port 7132
[in a different terminal]
./polorex txngen -port 7132 -iterations 100 -batchsize 250000 -parallelism 2
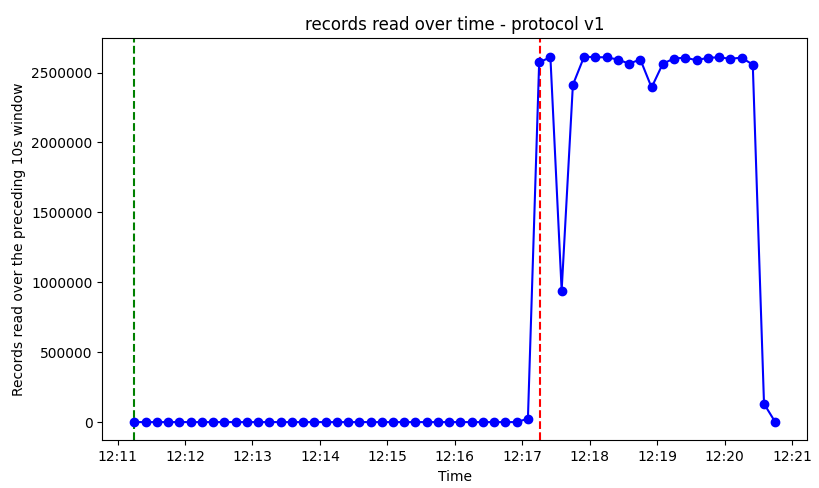
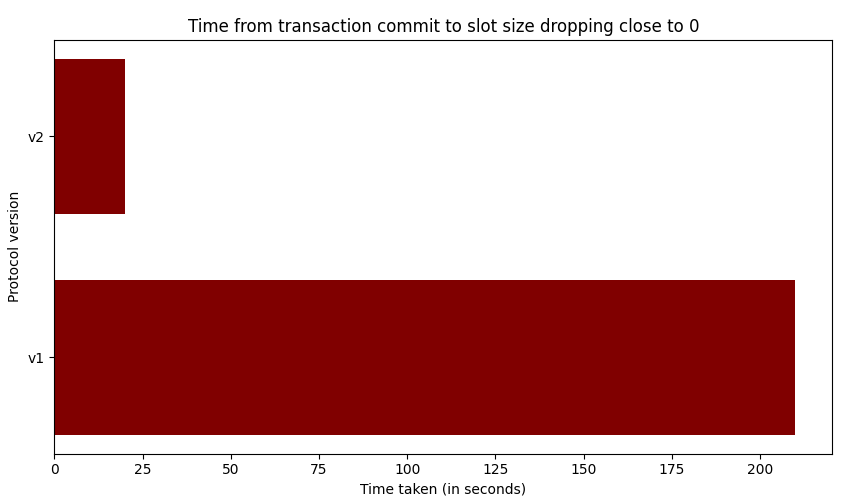
The transactions start at the green line and end at the red line. We can see how the transactions are being read only after they commit. It takes 3-4 minutes to decode both our transactions. Since we just committed 2 large transactions, the pgoutput plugin has to read a lot of WAL at once and then serialize it into 50 million INSERT messages to be sent over. While the graph shows that we are reading almost 250K inserts per second, but one can see how this could quickly go out of hand for larger transactions with wider schemas. We could quickly fall behind the primary server purely due to this decoding overhead.
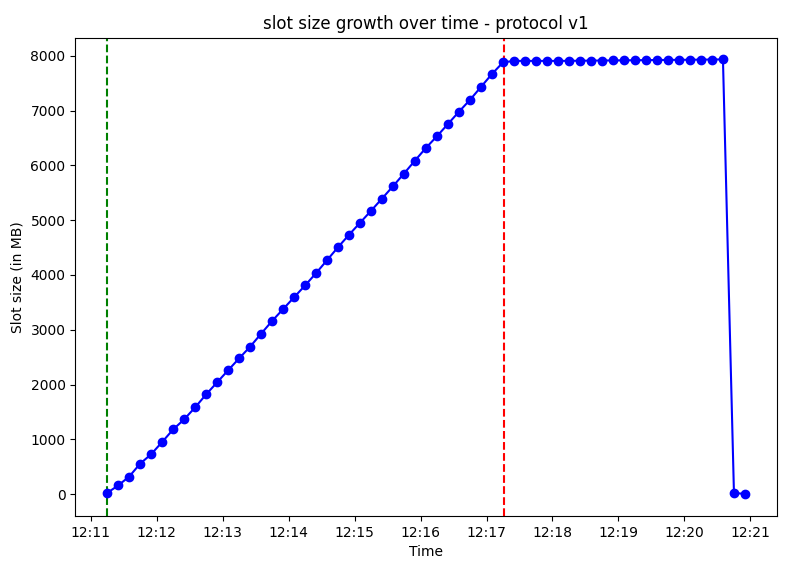
Another issue which follows from this but is less obvious is with regards to the size of the replication slot. This is basically the amount of WAL being retained for the slot to decode changes without losing any data. Looking at the graph, it quickly rises as the transactions progress, but also stays high until both transactions are read at which point it falls dramatically. This can be an issue in workloads with high throughput and large transactions - the WAL being retained can reach hundreds of gigabytes within a matter of hours, thereby consuming the entire disk space and crashing the Postgres server.
With this insight in mind, we can see how version 2's promise of allowing streaming of large in-progress transactions sound enticing. But there is also a simplicity in version 1 of only sending changes over when they are committed. We read a BeginMessage and everything from there onward is fair game to be replicated immediately. In contrast, an "in-progress" transaction could be rolled back at any point, and therefore all the changes read so far need to be staged somehow before being replicated.
v2 - rows down the stream
To begin with, we restart txnreader with a flag to ask it to use protocol version 2 while connecting to the slot. We then rerun the same txngen workload.
./polorex txnreader -port 7132 -protocol 2
[in a different terminal]
./polorex txngen -port 7132 -iterations 100 -batchsize 250000 -parallelism 2
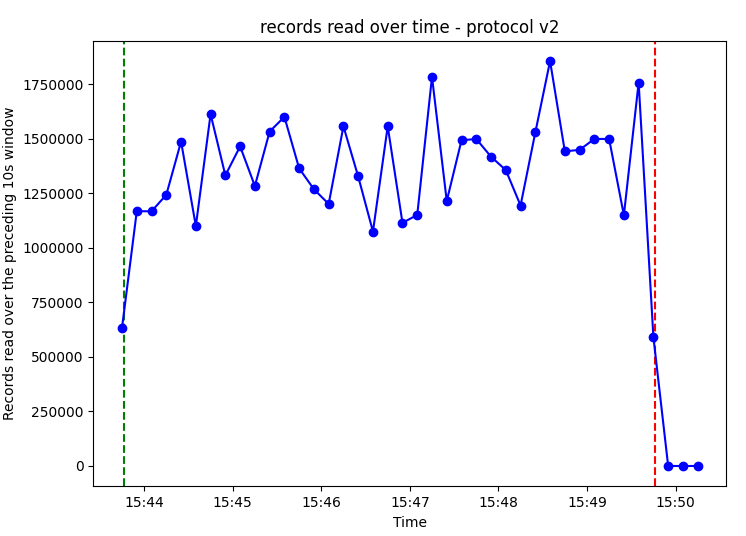
We are seeing a completely different story in terms of how the transactions are being processed here. It's clear that we're getting rows way before the transaction even commits. We're actually seeing streaming of in-progress transactions! Rows for a particular transaction come to us between a StreamStartMessage and StreamStopMessage, and we get several of these streams while rows are still being sent over. We are getting streams for both of our transactions before any of them commit, but we are still only reading 1 transaction at a time.
A transaction being streamed now commits using a StreamCommitMessage, but unlike the Commit message from earlier, we need to wait for this since the fate of the transaction is not known yet. Alternatively, we could receive a StreamAbortMessage which implies transaction rollback and so all our changes for said transaction should not be applied.
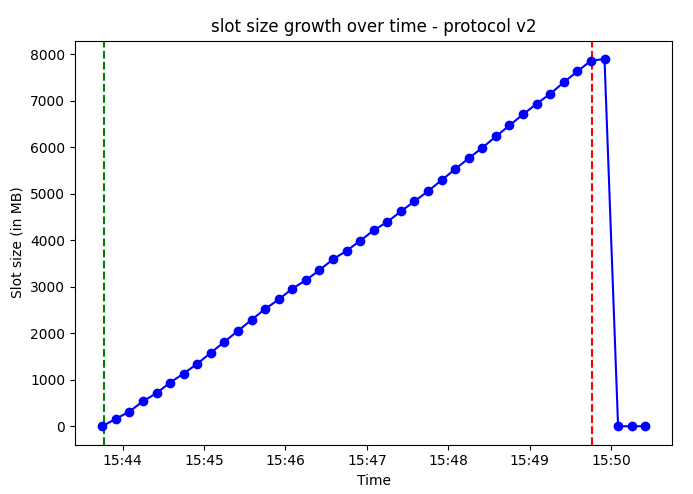
The improvements from streaming are nothing short of dramatic, we can see how transactions are fully read seconds after the rows finish inserting, approximately 4 minutes earlier compared to version 1. As a result, the slot size also decreases much more quickly.
Results - v2 enables faster decoding and shorter peak slot size duration
To reiterate, there is no magical improvement in transaction reading performance or peak slot size. The transactions themselves take about the same time to process and generate the same amount of WAL, but since the replication happens in parallel with the transaction, we see better performance.
In version 2, transactions are fully decoded, and the slot size decreases immediately after the transactions are completed, compared to version 1, which requires an additional 4 minutes. This can have drastic impact on workloads with high throughput and sizable transactions - version 2 can be very helpful in enhancing logical decoding performance and ensuring the slot size is kept in check!
v3 and v4 - 2PC and parallel apply
Version 3 introduces new message types to manage two-phase commit transactions. While significant in certain scenarios, the concept of two-phase commit remains relatively niche from an ELT standpoint.
Version 4 is less clear in its description, and even the documentation doesn't venture much farther than this. As it turns out, it doesn't refer to applying multiple transactions in parallel, but spreading out the load of applying a single large transaction over multiple processes in the standby. For this, new fields have been added to some existing messages. This is again a great feature in some workloads, but not very useful from the standpoint of something else pretending to be a Postgres standby.
Conclusion
Postgres logical replication is a powerful feature central to the distributed/HA Postgres ecosystem. By using version 2 of the logical replication protocol to stream in-flight transactions, we can efficiently manage WAL spikes during sizable transactions, enhancing logical decoding performance and mitigating disk full issues caused by replication slot growth. Additionally, this approach reduces the lag between the Postgres source and its readers.
At PeerDB, we're developing a feature that utilizes version 2 of the logical replication protocol to consume changes from a Postgres database before they are committed. We believe this feature will significantly benefit Postgres users grappling with issues related to replication slot growth. Overall, version 2 of the logical replication protocol presents a promising solution for optimizing Postgres replication processes and improving overall reliability and performance.




