
How can we make pg_dump and pg_restore 5 times faster?

pg_dump and pg_restore are reliable tools for backing up and restoring Postgres databases. They're essential for database migrations, disaster recovery and so on. They offer precise control over object selection for backup/restore, dump format options (plain or compressed), parallel table processing and so on. They ensure a consistent database snapshot is dumped and restored.
However, they are single-threaded at the table level. This significantly slows down the dump and restore of databases with a star schema common in real-world applications such as Time series and IoT. For databases over 1 TB, pg_dump and pg_restore can take days, increasing downtime during migrations and RTOs in disaster recovery scenarios.
In this blog, we'll discuss an idea called "Parallel Snapshotting". This idea could be integrated into Postgres upstream in the future to make pg_dump and pg_restore parallelizable at a single table level. Parallel Snapshotting has already been implemented in PeerDB, an open-source Postgres replication tool. We will also cover a few interesting benchmarks of migrating a large table of 1.5TB from one Postgres Database to another with and without Parallel Snapshotting.
A quick primer on pg_dump and pg_restore
pg_dump is the most reliable way to back up a PostgreSQL database. It enables the backup of a database at a consistent snapshot; that is, the backup guarantees a state that existed previously. The backup generated by pg_dump is a logical representation of the data in PostgreSQL, not a copy of the PostgreSQL data directory. It captures objects as they appear in PostgreSQL.
pg_restore is the most reliable way to restore a backup generated by pg_dump from one PostgreSQL database to another.
Both pg_dump and pg_restore are Postgres-native; that is, they come packaged with community Postgres and can be used as command-line utilities, similar to psql.
pg_dump and pg_restore offer fine grain control
They provide fine-grained control to manage the backup and restore processes. Below are a few flags that are commonly used:
You have the
-fflag, which lets you decide on data formats such as plain text or compressed gzip. Compressed dumps are quite helpful when you have limited network bandwidth or want to save on network costs.To speed up the backup and restore process, you can use the
-jflag to dump and restore multiple tables in parallel.You can pick and choose specific database objects you want to backup and restore, including tables and schemas.
You can also choose to dump only the schema or only the data using the
schema-onlyanddata-onlyflags.There are many more flags that they provide that can be found in community docs.
pg_dump and pg_restore can be very slow for large tables
pg_dump and pg_restore are single threaded at a table level
There is a painful issue that users often run into with pg_dump and pg_restore. pg_dump and pg_restore can be very slow for large tables. This is because they are single threaded at table level. They can dump and restore multiple tables in parallel but for a single table they are single threaded.
This means that in use cases where you have a single fact table and multiple dimension tables, pg_dump and pg_restore can get bottlenecked on the large fact table. This is very common in the star schema data-model which is used by multiple real-world use-cases such as IoT, Timeseries, Data Warehousing and so on.
Migrating a 1.5TB table can take 1.5 days
The impact of the problem described above can be significant. Using pg_dump and pg_restore to migrate a 1.5 TB pgbench_accounts table from one Postgres database to another took 1.5 days. The benchmark was conducted under optimal conditions, i.e., using the correct flags and region collocating the source, target, and the VM on which pg_dump and pg_restore were running, among other factors. This 1.5-day downtime is substantial when migrating or recovering mission-critical databases.
Parallel Snapshotting to make pg_dump & pg_restore multi-threaded per table
Now, let's explore a concept called Parallel Snapshotting, which could make pg_dump and pg_restore multi-threaded at the single table level. Note that Parallel Snapshotting is not currently implemented in the upstream versions of pg_dump and pg_restore. It represents an idea/design that could enhance pg_dump and pg_restore in the future.
Below video captures migrating 5GB of data from Postgres to Postgres within a min using the Parallel Snapshotting feature in PeerDB.
CTID forms the basis of Parallel Snapshotting
CTID forms the basis of Parallel Snapshotting. Every row in a Postgres table has an internal column called CTID, also known as the tuple identifier. CTID is unique for each row of the table. It represents the exact location of the row on disk—it is the combination of the page/block number and the page offset. You can also query the CTID column for a table through a simple SELECT as you are seeing in the below image.
Parallel Snapshotting - Logically Partition the Table by CTID and COPY Multiple Partitions Simultaneously
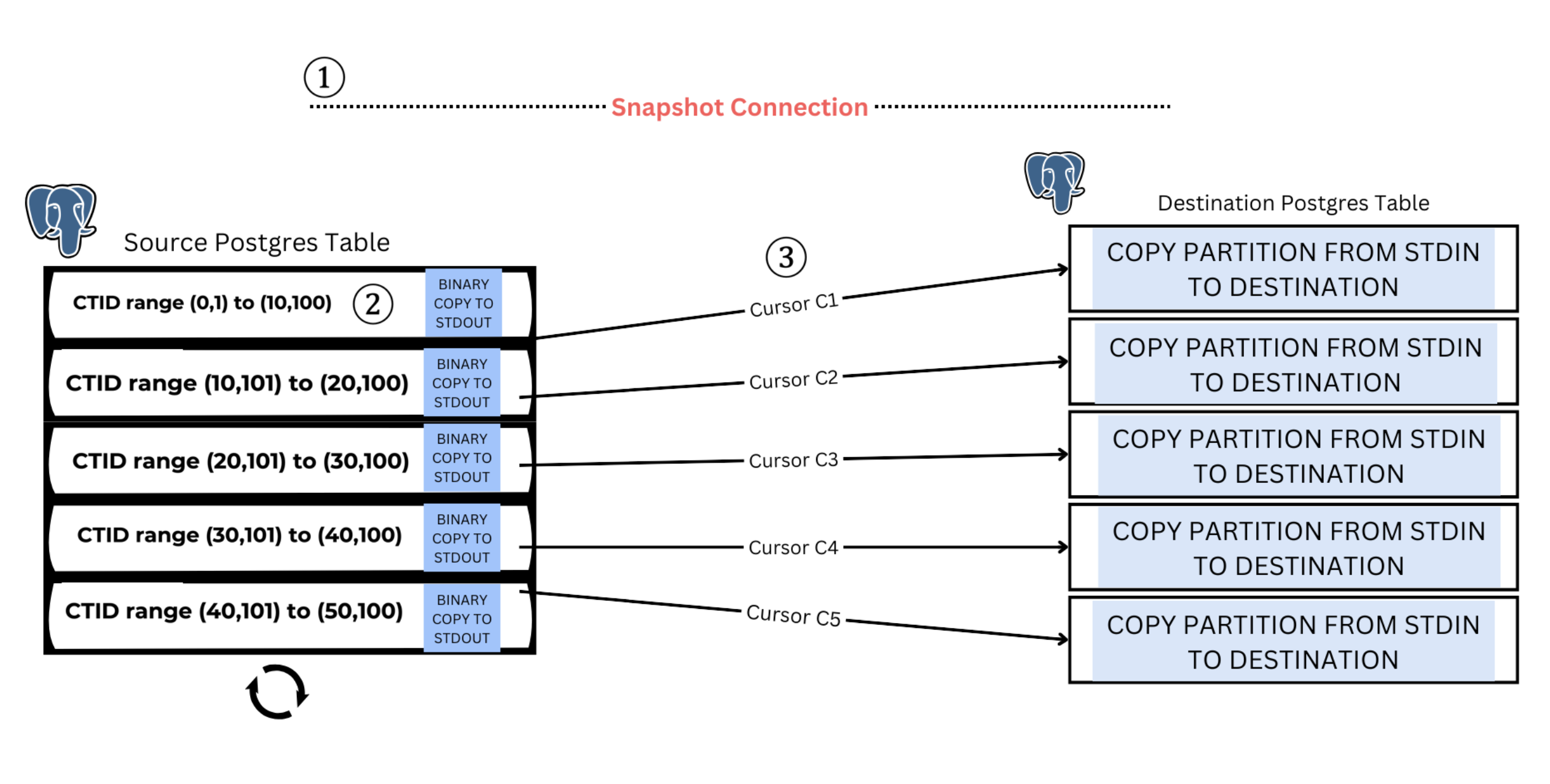
Let's dive into the design of Parallel Snapshotting:
First, create a Postgres Snapshot using the function
pg_export_snapshot(). This ensures that the dump and restore operate on a consistent snapshot of the database.Second, using that snapshot, logically partition the large table based on CTIDs, i.e., create CTID ranges that encapsulate the table.
Once that is done, copy multiple such logical partitions in parallel from the source to the target.
Essentially, you are running SELECT statements with these CTID ranges to read data from the source and write it to the target.
The SELECT statements with CTID ranges are very efficient because they use tid range scans, which are similar to index lookups on the CTID column.
Also, note that you are reading data in the order of how it is stored on the disk.
We are using
COPY WITH BINARYtoSTDOUTand fromSTDIN, which makes the dump and restore simultaneous.We are also using cursors to ensure that the dump doesn’t exhaust memory.
Migrating a 1.5TB table 5 times faster with Parallel Snapshotting
At PeerDB, we are building a Postgres replication tool to provide a fast and cost-effective way to move data from Postgres to data warehouses such as Snowflake, BigQuery, ClickHouse, PostgreSQL, and queues like Kafka, Redpanda, Google PubSub, Azure Event Hubs, etc.
To enable faster migrations from one Postgres database to another, we have implemented Parallel Snapshotting within our product. Through this feature, our customers are able to move terabytes of data in a few hours versus days.
We did the same above benchmark to move a 1.5 TB pgbench_accounts table from one Postgres database to another, and it took just 7 hours with PeerDB. This was 5x faster than using pg_dump and pg_restore. This speedup was possible through the Parallel Snapshotting feature. The performance can be further improved by increasing the number of parallel threads for the migration and by using more beefier Postgres source and target databases.
Conclusion and References
The intent of this blog is to share the design principles we followed to enable faster database migrations and discuss how they can be extended to enhance pg_dump and pg_restore in the future. Hope you enjoyed reading the blog. Sharing a few relevant links for reference:
Try PeerDB Open Source for fast Postgres migration and replication
Try PeerDB Cloud, the fully managed offering of PeerDB




