
Parallelized Initial Load for CDC-based streaming from Postgres
plus more in PeerDB v0.7.1

Search for a command to run...
plus more in PeerDB v0.7.1
No comments yet. Be the first to comment.
Today, we’re excited to announce the private preview of the Postgres Change Data Capture (CDC) connector in ClickPipes! This enables customers to replicate their Postgres databases to ClickHouse Cloud in just a few clicks and leverage ClickHouse for ...

Last month, we acquired PeerDB, a company that specializes in Postgres CDC. PeerDB makes it fast and simple to replicate data from Postgres to ClickHouse. A common question from PeerDB users is how to model their data in ClickHouse after the replicat...

Providing a fast and simple way to replicate data from Postgres to ClickHouse has been a top priority for us over the past few months. Last month, we acquired PeerDB, a company that specializes in Postgres CDC. We're actively integrating PeerDB into ...

We are thrilled to join forces with ClickHouse to make it seamless for customers to move data from their Postgres databases to ClickHouse and power real-time analytics and data warehousing use cases. We released the ClickHouse target connector for Po...

At PeerDB, security has always been a top priority. Our customers trust us with their critical data, and we are dedicated to upholding the highest standards of data protection and security. We are excited to announce that PeerDB has achieved SOC 2 Ty...

PeerDB is a specialized data-movement tool for Postgres. Currently, it supports 2 modes of streaming data in and out of Postgres - Change-data-capture (CDC) based streaming and Query-based streaming. We support a bunch of sources and targets for both of these streaming modes. See supported connectors for more details.
Using these streaming modes, you can accomplish multiple real-world use cases incl. database migrations; real-time operational analytics - streaming of transactional data in Postgres to data warehouses for analytics; periodic backups - archive older data in Postgres to cold storage (S3, Blob) and many more.
v0.7.1 is PeerDB's most recent release with a bunch of enhancements for faster, richer and more reliable data movement for Postgres. This blog does a deep dive into a few highlights:
Parallelized Initial Load for CDC-based streaming.
Reliability and stability improvements
New connectors - Azure Event Hubs and SQL Server
Metrics and Monitoring (preview)
PeerDB now allows you to copy existing data (a.k.a initial snapshot or initial load) in your Postgres tables to the target data store before replaying changes from the logical replication slot (CDC). The initial snapshot is parallelizable at a per-table level. We do this by logically partitioning the table based on internal tuple identifiers (CTID) and parallelly streaming those partitions to the target data store. The implementation is inspired by this DuckDb blog. Based on the load you can afford to put on the source Postgres database, you can configure the parallelism for the initial snapshot.
This feature has a significant impact on load times - you can sync TBs of data in a few hours vs. days. Below are a few real-world use cases that can drastically benefit from this feature:
Faster Postgres to Postgres migrations - If you are migrating your Postgres database on-prem to the cloud or migrating across managed providers, you can get the fastest and most reliable migration experience with PeerDB. 100s of GB can be migrated in a few minutes and TBs can be migrated in a few hours.
Faster Postgres to BigQuery/Snowflake full syncs and resyncs - As a part of setting up a real-time CDC-based pipeline from Postgres to Snowflake, one of our customers was able to load 10 billion rows in ~12 hours. Their existing data movement tool took 3 days and a few other tools never finished.
Based on the target data store, there are other performance optimizations that PeerDB does under the covers for the initial snapshot of the data.
For Postgres to Postgres streaming, PeerDB uses the COPY command with BINARY format to read from the source and write to the target. This enables byte-to-byte copy between source and target Postgres databases, reducing serialization/deserialization overhead and enhancing the speed of data transfer. You can follow the steps in this doc to experience PeerDB for Postgres to Postgres migrations.
For Postgres to Snowflake (or BigQuery) streaming, data is converted to Avro format, staged and pushed to the target. Avro enables data to be stored in binary (compressed) format and still supports a wide variety of data types (unlike parquet). This enables fast data movement, without compromising data integrity. You can follow the steps in this doc to experience PeerDB for real-time CDC-based streaming incl. Parallelized Initial Load from Postgres to your data warehouse.
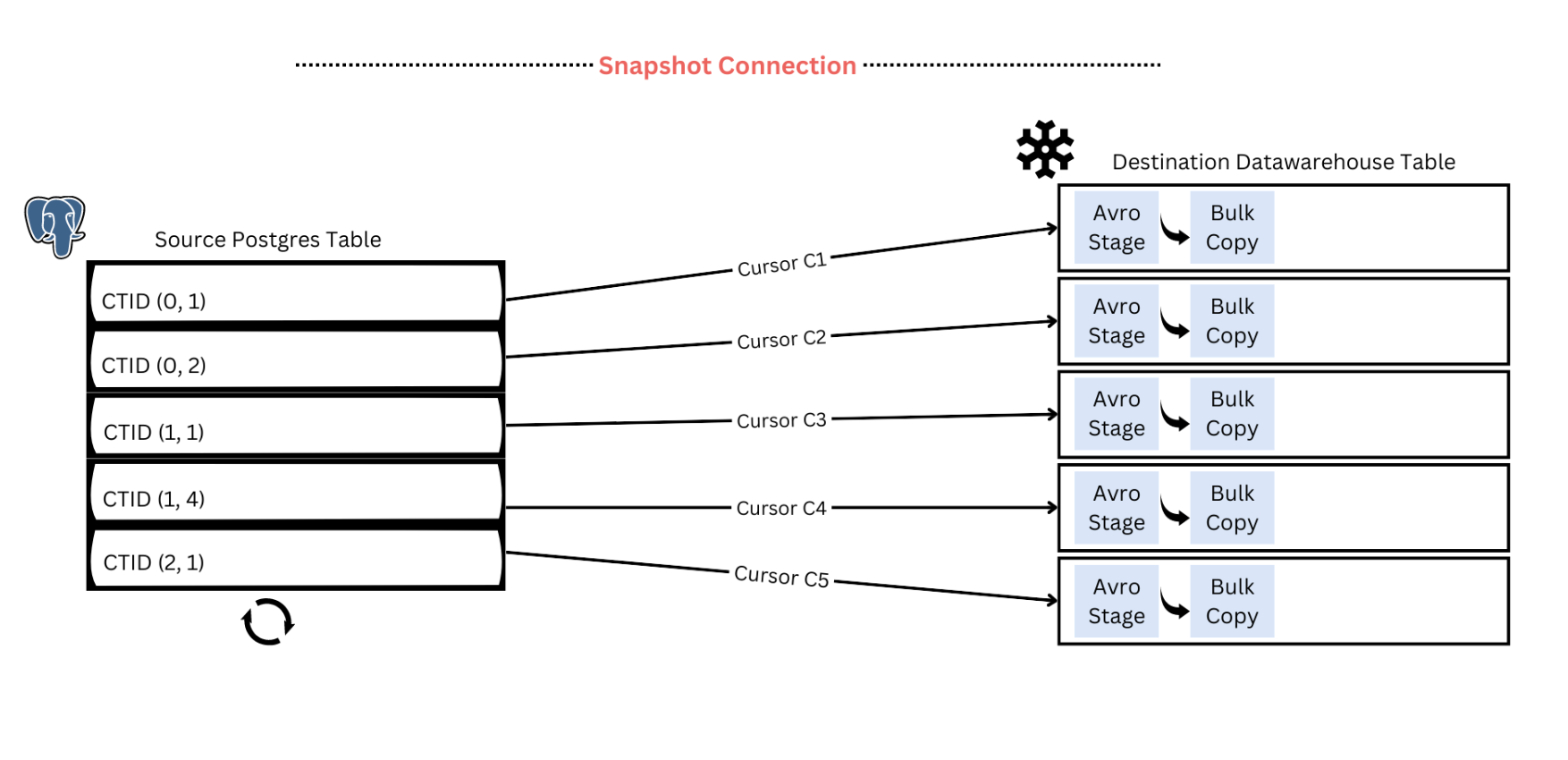
Below demo shows the Parallelized Initial Load feature in action to replicate ~100 million from Postgres to Postgres in less than 5 minutes.
In our latest update, v0.7.1, a significant focus has been placed on enhancing reliability and stability. To achieve this, we dedicated an entire sprint to develop a robust testing framework designed for scale testing across our entire technology stack. This involved crafting tables and schemas to rigorously test a myriad of edge cases—ranging from handling columns larger than 15MB to dealing with wide tables and varying data types. To simulate real-world conditions, we loaded approximately 300GB of data into our source PostgreSQL database. The objective was to comprehensively assess performance across different scenarios, including data transfers from PostgreSQL to PostgreSQL, PostgreSQL to Snowflake, and PostgreSQL to BigQuery, both in initial load conditions and with Change Data Capture (CDC).
Through this exhaustive testing, we were able to surface issues that only became apparent at scale. These issues have been addressed, resulting in a significantly smoother operation. Additionally, we've augmented our logging capabilities to provide more insightful analytics. In our orchestration engine (temporal), we've also ramped up the implementation of heartbeats to monitor system health more aggressively. These are just a few of the many stability improvements you'll find in PeerDB v0.7.1, as we continue our commitment to delivering a reliable and robust data movement solution for Postgres.
As a part of this release, we also added 2 new connectors:
Azure Event Hubs as a target for CDC-based streaming from Postgres - With this you can stream CDC (logical replication) changes in real-time from your Postgres database to Azure Event Hubs. More details can be found here. Under the covers, PeerDB creates 1 Event Hub topic per Postgres table and writes CDC changes in parallel across topics. We enable you to configure the parallelism and the batch size while syncing records to Event Hubs.
SQL Server as a source for Query-based streaming to Postgres - Now you can stream the results of any SQL query on SQL Server to Postgres. The streaming can be configured to be an incremental or a one-time load. More details can be found here. One of our customers is testing PeerDB to periodically stream data from their SQL Server databases on the edge to their centralized Postgres data warehouse.
As a part of v0.7.1, we released our first take on metrics and monitoring. Our goal with this effort is to provide full operational visibility into all the data streaming jobs (a.k.a. MIRRORs) that are running on your PeerDB cluster.
Metadata tables - We introduced 4 metadata tables in the peerdb_stats schema that capture useful information about the ongoing MIRRORs. They capture information such as the status of MIRRORs, the progress of MIRRORs, streaming throughput, latency/lag and so on. As PeerDB is Postgres-compatible, you can connect these metadata tables to your existing monitoring tools viz. data-dog, new-relic, Grafana and integrate PeerDB with your existing monitoring eco-system.
Grafana Dashboard - We also package Grafana and Prometheus as a part of our docker stack. Grafana dashboard is available on port 3000. It captures throughput and lag related details as below:
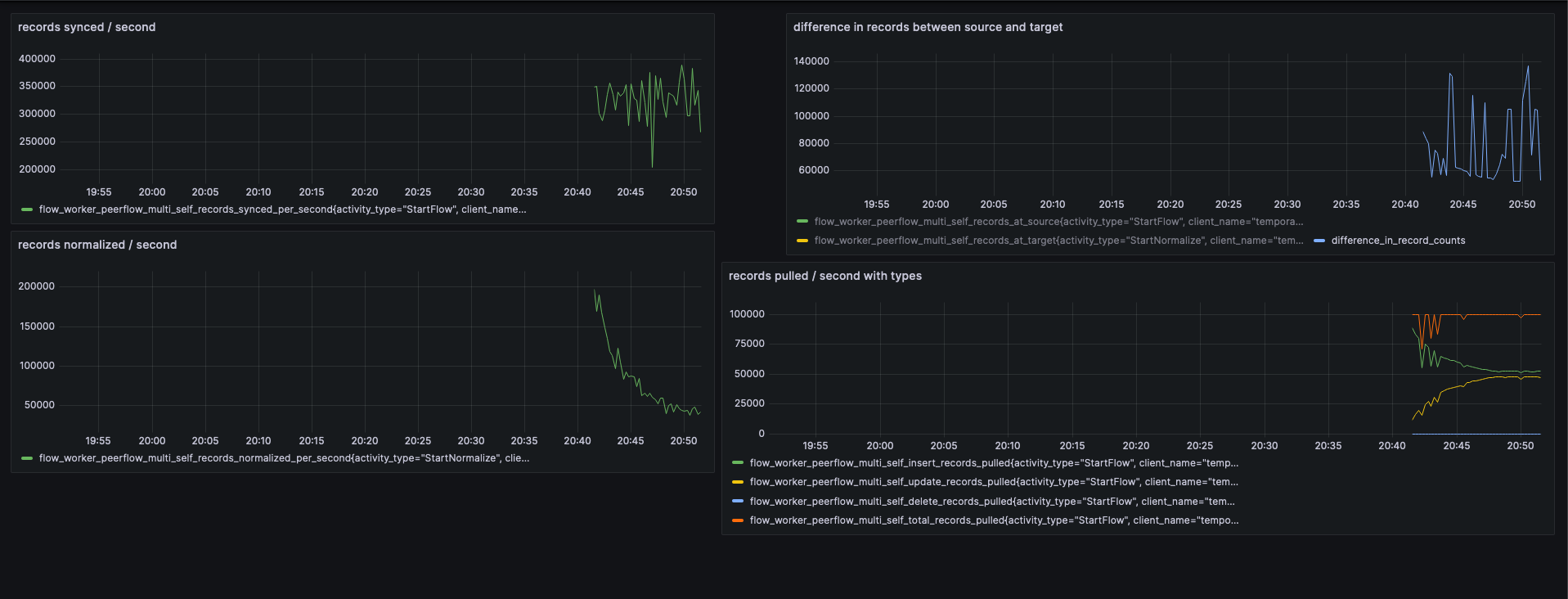
We are constantly evolving our metrics and monitoring story. You can anticipate many more enhancements on this end in our future releases.
Hope you enjoyed reading the blog. If you want to get started with PeerDB v0.7.1, these links should prove useful: