
Data Types Need Care during Database Replication
Search for a command to run...
No comments yet. Be the first to comment.
Today, we’re excited to announce the private preview of the Postgres Change Data Capture (CDC) connector in ClickPipes! This enables customers to replicate their Postgres databases to ClickHouse Cloud in just a few clicks and leverage ClickHouse for ...

Last month, we acquired PeerDB, a company that specializes in Postgres CDC. PeerDB makes it fast and simple to replicate data from Postgres to ClickHouse. A common question from PeerDB users is how to model their data in ClickHouse after the replicat...

Providing a fast and simple way to replicate data from Postgres to ClickHouse has been a top priority for us over the past few months. Last month, we acquired PeerDB, a company that specializes in Postgres CDC. We're actively integrating PeerDB into ...

We are thrilled to join forces with ClickHouse to make it seamless for customers to move data from their Postgres databases to ClickHouse and power real-time analytics and data warehousing use cases. We released the ClickHouse target connector for Po...

At PeerDB, security has always been a top priority. Our customers trust us with their critical data, and we are dedicated to upholding the highest standards of data protection and security. We are excited to announce that PeerDB has achieved SOC 2 Ty...

Moving data from one data store to another means finding common ground. Data stores speak in terms of data types. Two data stores will never have a perfect overlap when it comes to what data types they support. It's the responsibility of a data movement tool to ensure efficient and native data type mapping during replication.
This blog discusses the importance of a carefully designed data type mapping during database replication. It also talks about how PeerDB handles data type mapping, with practical examples.
Below are the benefits of a carefully designing data type mapping during replication, involving the use of the most optimal native data types for both source and target.
Saves Transformation Costs: JSONs are tricky, so let's just map JSONs of PostgreSQL to STRINGs in Snowflake. This is easy enough but not a good idea. Every consumer of the warehouse (ex: DBT jobs) would need to transform the STRING to a JSON. This could drastically increase Warehouse costs. Mapping JSON in Postgres to the native VARIANT type in Snowflake would help avoid those transformation costs.
Query richness: Storing data in the target system's native data types, such as enables users to fully utilize its advanced querying capabilities. For example, storing JSON in its native format allows for efficient use of JSON-specific functions and native GEOSPATIAL types enables complex spatial queries and analyses.
Reduces Tech Debt: Consider a scenario where Geospatial (POSTGIS data) from PostgreSQL is mapped as STRINGs in Snowflake. In this case, the data engineer responsible for building DBT pipelines in Snowflake will need to convert these STRING types into Snowflake's native geospatial types. This means extra code and more effort! Why not have a data movement tool do this for you automatically, reducing technical debt?
At PeerDB, our core engineering philosophy is to be tailored to each individual data store - the way each behaves, the features each provides - these store-specific intricacies are leveraged to maximum effect.
One of the approach we take is to have a mapping per data type, per store. PostgreSQL to Snowflake and PostgreSQL to Google BigQuery are two distinct code paths, allowing us to develop robust, tailored pipelines. Let's look at a few case studies.
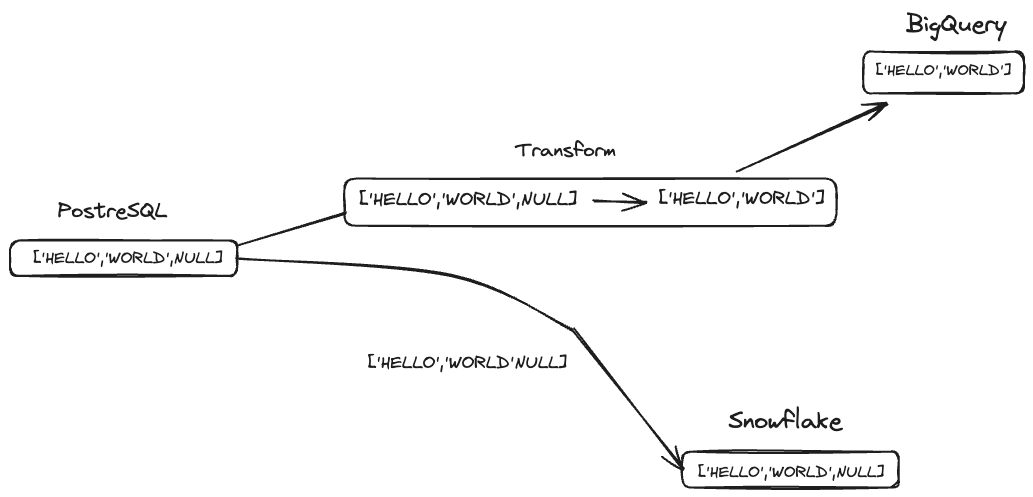
Let's consider the task of mapping a TEXT[] array of PostgreSQL to Snowflake and BigQuery. They both support their own ARRAY types, of course. We can reuse the same piece of code to sync these types to both these stores!
So we go ahead and kick off replication. Everything looking good for Snowflake. Alas, you see that your flow to BigQuery fails for an array such as this:
-- BigQuery doesn't allow NULLs in Arrays
SELECT ['HELLO','WORLD',NULL]
Array cannot have a null element; error in writing field f0_
Turns out, BigQuery doesn't like having NULLs in arrays during their insertion. We'll have to strip those arrays of the nulls. Now here's the loss - we've already committed to a single mapping, meaning we will be removing nulls in Snowflake arrays for no reason.
PeerDB avoids this by having flags and gates to transform data according to where it's going. In this case, we are able to continue to sync such arrays to both the data warehouses as natively possible.
Now let's try syncing a JSON value like {"rating": 4.553435} to BigQuery. Luckily for us, it provides a PARSE_JSON function we can use to parse JSON formatted strings to the actual JSON. Great! Except we're hit with another complaint:
4.553435 cannot round-trip through string representation
Turns out, BigQuery handles floating point values differently, and for some reason refuses to accept this harmless number.
Upon some research, we see that PARSE_JSON accepts an argument called wide_number_mode which must be set to the value round - this tells BigQuery that it can round these numbers if it thinks they're too long.
The only reason we're able to implement these root-level fixes is because our architecture defines data by their type and their destination, rather than just the type.
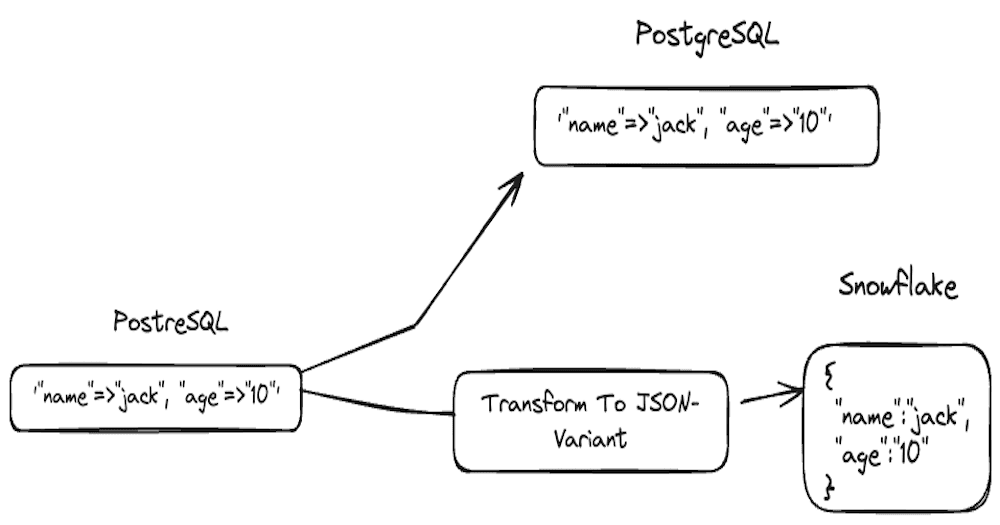
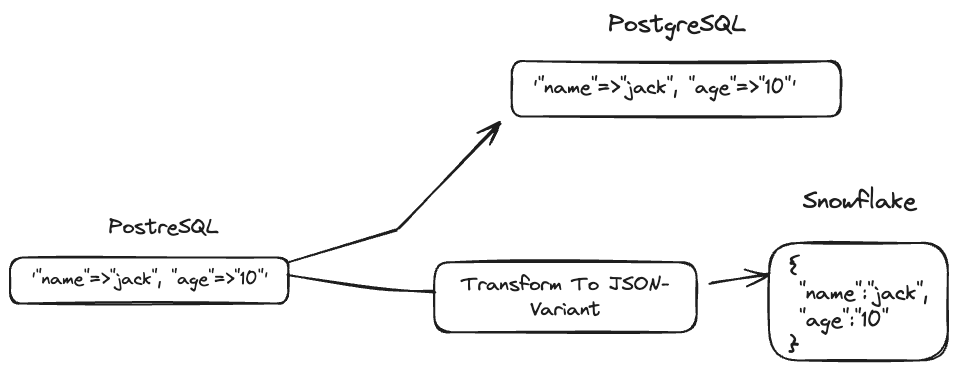
PostgreSQL's HStore was the first unstructured data type to release for it. It is a simple key-value pair data type with a great deal of flexibility. Let's say we were to sync these HStores to PostgreSQL (destination) and Snowflake.
Well, Snowflake doesn't document a HStore type of their own, like PostgreSQL does. At this point, many would be tempted to simply write HStores as strings to Snowflake.
However that is not in the spirit of a data type which is of a key-value pair form. We would like to be able to query the HStore as we would be able to in PostgreSQL. Therefore the better choice would be to sync them as VARIANTs in Snowflake so customers can leverage Snowflake's Semi-Structured Data Querying.
PeerDB supports all the primitives types and their arrays as expected. These include integers, timestamp, date, boolean, text and nulls.
Below is a look at how PeerDB maps a few complex types.
| PostgreSQL | Snowflake | BigQuery |
| JSON | JSON-Compatible VARIANT | JSON |
| JSONB | VARIANT | JSON |
| GEOGRAPHY | GEOGRAPHY (WKT) | Geography (WKT) |
| GEOMETRY | GEOMETRY (WKT) | Geography (WKT) |
| HStore | JSON-Compatible Variant (respects HStore intricacies) | JSON |
| ENUM | STRING | STRING |
| ARRAY | ARRAY | ARRAY |
Hope you enjoyed reading this blog on importance of Data Type mapping during Database Replication. Speaking of data types, feel free to check out these other resources on the same topic: