
Using Temporal to Scale Data Synchronization at PeerDB

At PeerDB, we're tackling the challenge of scaling data synchronization across distributed systems. One of the cornerstones of our approach is Temporal, an open-source workflow orchestration platform. This platform shines when it comes to managing retries, long-running state, ensuring idempotency, and much more. In this blog post, we’ll guide you through how we have incorporated Temporal into our data synchronization workflows.
Scaling Data Synchronization
Before diving into the specifics, it's essential to comprehend the complexities involved in data synchronization across distributed systems. Data synchronization involves streaming data changes (Change Data Capture or CDC) and replicating the results of a query on a source system. These operations must be robust, stateful, and often long-running. With the advent of various data sources and destinations in a distributed environment, these challenges compound.
To tackle these, we architected a solution focusing on statefulness, idempotency, retryability, and the separation of concerns. The cornerstone of this architecture is an interface we call Connector.
The Role of Connector
type Connector interface {
Close() error
ConnectionActive() bool
...
PullRecords(req *model.PullRecordsRequest) (*model.RecordBatch, error)
SyncRecords(req *model.SyncRecordsRequest) (*model.SyncResponse, error)
...
}
Connector is the interface at the heart of our architecture, encapsulating the logic for various operations critical for our data synchronization tasks. The methods range from maintaining the state (GetLastOffset), pulling and syncing records (PullRecords, SyncRecords), to ensuring the idempotency of operations, and setting up necessary pre and post operations.
For example, PullRecords and SyncRecords are idempotent. In other words, they can be called multiple times with the same request without changing the result. This is a vital attribute in a distributed system where network issues could lead to duplicated or retried requests.
Incorporating Temporal
Temporal has proven to be an invaluable tool for simplifying the management of these workflows. We use Temporal to orchestrate our two workflows, the PeerFlowWorkflow (for CDC) and the QRepFlowWorkflow (for query replication).
Temporal enables us to divide these workflows into multiple activities, tailored to the requirements of the sources and destinations. This segregation provides us with granular control and visibility over the state and progress of each operation, making the system more reliable and easier to maintain.
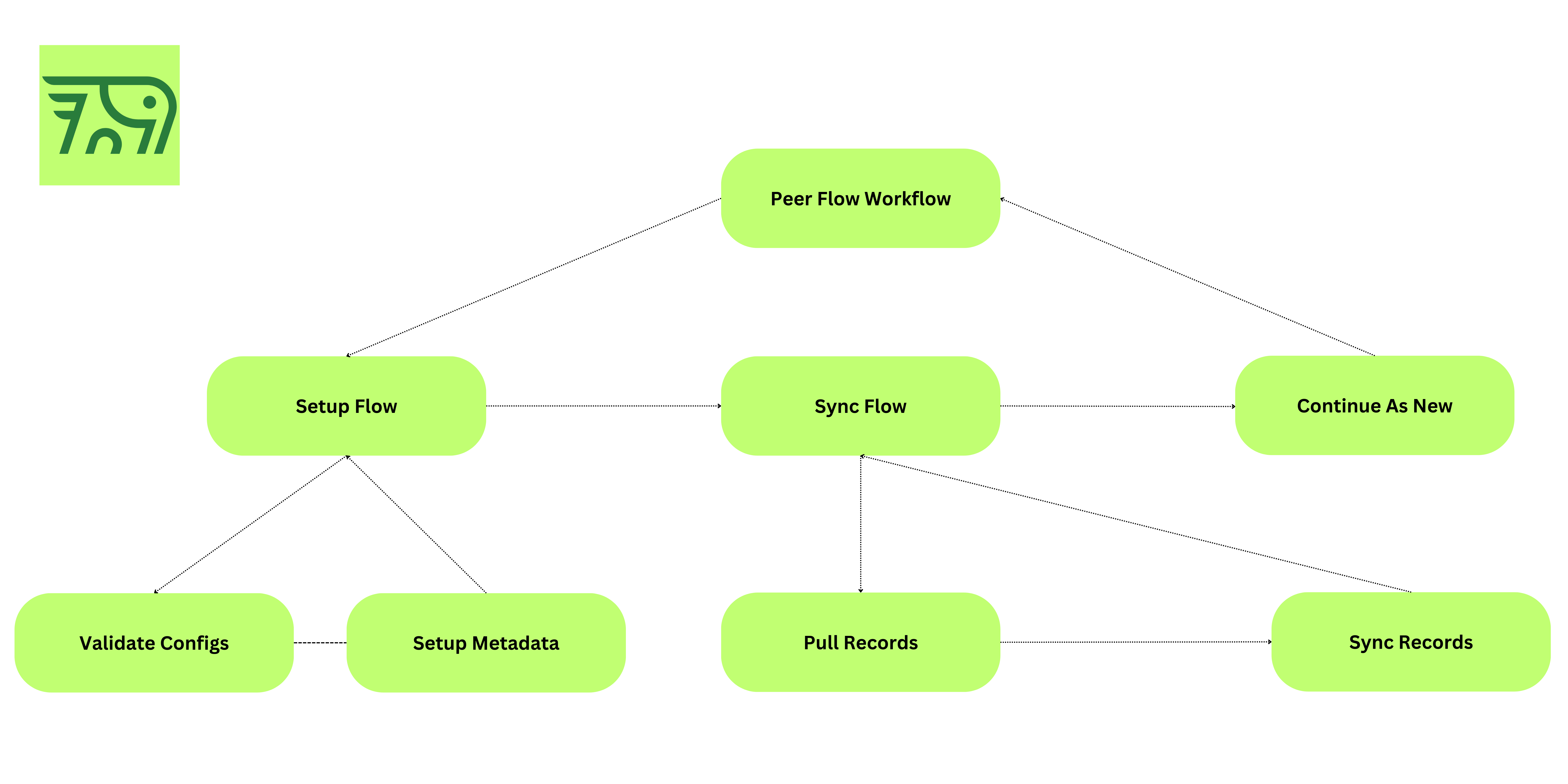
Enhancing Retryability
Temporal shines when it comes to handling retries. In distributed systems, failure is inevitable. However, having a system designed to embrace retries ensures that temporary issues don’t lead to permanent data loss or inconsistencies. Temporal's in-built support for retries means that if a workflow fails due to a transient issue, it can automatically retry the operation, making our system far more resilient.
Scaling with Temporal
func (w *Workflow) StartWorkflow(...) {
...
err = w.TemporalClient.ExecuteWorkflow(...)
...
}
With Temporal and our Connector interface at our disposal, we have crafted a system that scales gracefully with our needs. Each source and destination can implement its instance of the Connector interface, enabling easy expansion to new data sources or destinations without impacting the existing ones. This design is inherently scalable and flexible.
Temporal also aids us in managing long-running operations. Functions such as data streaming and replication are inherently long-running. Temporal ensures these operations are carried out efficiently without the need to complete in a single step, thus ensuring smooth operation even under heavy load or over extended periods.
Deployment Advantages
One of the unexpected benefits of this architecture is the ease of deployment. Thanks to the modularity of our design, PeerDB can easily be containerized and deployed using Docker. Furthermore, deploying on Kubernetes clusters allows us to scale horizontally and manage our services more efficiently, offering improved reliability and resource usage.
git clone --recursive <https://github.com/PeerDB-io/peerdb.git>
docker compose up
Wrapping Up
Through Temporal and our Connector interface, PeerDB has devised a robust and scalable architecture for data synchronization in distributed systems. By handling complex issues like state management, idempotency, retryability, and separation of concerns, we've made our system incredibly reliable and robust.
Temporal's workflow orchestration capabilities have been a game-changer, enabling us to manage and scale our data synchronization tasks efficiently. By leveraging Temporal's features and coupling them with a carefully designed Connector interface, we're propelling PeerDB's data synchronization capabilities to new heights.
If you are interested in handling larger, more complex data synchronization tasks in your distributed systems, we invite you to try out PeerDB. We're excited to share the possibilities that this combination of Temporal and PeerDB can open up for your data needs. Visit our website or Github page to get started.
PeerDB is built to scale, ready to deliver!




