
Postgres to ClickHouse Real time Replication using PeerDB

Search for a command to run...
could we manage peerdb OSS mirrors with declarative YAML config files instead of using UI?
Yep, PeerDB provide a postgres-compatible SQL Layer to create snd mamage peers and mirrors https://docs.peerdb.io/sql/reference
Today, we’re excited to announce the private preview of the Postgres Change Data Capture (CDC) connector in ClickPipes! This enables customers to replicate their Postgres databases to ClickHouse Cloud in just a few clicks and leverage ClickHouse for ...

Last month, we acquired PeerDB, a company that specializes in Postgres CDC. PeerDB makes it fast and simple to replicate data from Postgres to ClickHouse. A common question from PeerDB users is how to model their data in ClickHouse after the replicat...

Providing a fast and simple way to replicate data from Postgres to ClickHouse has been a top priority for us over the past few months. Last month, we acquired PeerDB, a company that specializes in Postgres CDC. We're actively integrating PeerDB into ...

We are thrilled to join forces with ClickHouse to make it seamless for customers to move data from their Postgres databases to ClickHouse and power real-time analytics and data warehousing use cases. We released the ClickHouse target connector for Po...

At PeerDB, security has always been a top priority. Our customers trust us with their critical data, and we are dedicated to upholding the highest standards of data protection and security. We are excited to announce that PeerDB has achieved SOC 2 Ty...

Today we at PeerDB are introducing the ClickHouse target connector in Beta. With this you can seamlessly replicate data in Postgres to ClickHouse with low latency and high throughput. ClickHouse was one of the most asked connector from our customers, so we prioritized it right after our initial set of targets which includes Snowflake, BigQuery and Postgres.
In this blog, we'll cover the use cases that Postgres to ClickHouse replication enables, followed by a practical demo showing low latency (10s) replication from Postgres to ClickHouse using PeerDB, and conclude with how we built this Connector.
Operational Analytics or HTAP - Replicating data from Postgres to ClickHouse enables real-time analytics on operational data without compromising transactional performance, creating an efficient Operational Data Warehouse or an HTAP environment. Postgres handles transactional (OLTP) workloads, while ClickHouse enables fast analytics (OLAP) on transactional data.
ClickHouse as Data Warehouse - ClickHouse is considered a cost-effective Data Warehouse due to its open-source nature, columnar storage, data compression, and parallel processing capabilities, which enhance analytics performance on large datasets while minimizing hardware costs. In this scenario, Postgres to ClickHouse replication enables move your application (OLTP) data to your Data Warehouse for centralized analytics.
In this section, we'll walk through an example of Postgres to ClickHouse replication using PeerDB.
You can use any Postgres database in the cloud or on-prem. I am using RDS Postgres for this setup. The Postgres database has a goals table which is constantly getting ingested with 2500 rows per second.
CREATE TABLE public.goals (
id bigint PRIMARY KEY GENERATED BY DEFAULT AS IDENTITY,
owned_user_id UUID,
goal_title TEXT,
goal_data JSON,
enabled BOOL,
ts timestamp default now()
);
/* Insert 5000 records at a time into goals table */
INSERT INTO public.goals (owned_user_id, goal_title, goal_data, enabled)
SELECT gen_random_uuid(), 'tiTLE', '{"tags": ["tech", "news"]}', false
FROM generate_series(1, 5000) AS i;
/* Using psql's \watch keep insert 5000 records every 2 seconds */
postgres=> \watch
--INSERT 0 5000
--INSERT 0 5000
--INSERT 0 5000
You can create ClickHouse using its Docker container on an EC2 instance or use ClickHouse Cloud. In my test I used ClickHouse Cloud. I created a separate database called peerdb, where I'll be replicating the goals table from Postgres.
You can use PeerDB Open Source or PeerDB Cloud to deploy a PeerDB instance. For the scope of this demo, I'll be using the PeerDB Cloud's Micro offering which has a 1-month free trial.
In the PeerDB world, Peers are data stores. Creating Peers lets PeerDB know which data stores the replication will be set up between. You can use PeerDB's UI to create the Postgres and the ClickHouse Peers.
In the PeerDB world, a Mirror represents replication from a source peer to a target peer. You can use PeerDB's UI to create a MIRROR for replicating data from Postgres to ClickHouse.
Data Freshness
You can set the Sync Interval to control data freshness in ClickHouse; I set this interval to 10 seconds, which was feasible specifically because of ClickHouse. Such a short interval wouldn't have been practical with other Data Warehouses like Snowflake or BigQuery. This is because they don't handle real-time data ingestion as flexibly as ClickHouse; and real-time ingests would keep them active for longer, incurring high costs, unlike with ClickHouse.
MIRROR = Initial Load + Change Data Capture
If you observe, I created a Change Data Capture (CDC) based MIRROR that replicates data using Postgres' Write-Ahead Log (WAL) and Logical Decoding. It involves two steps:
An initial load that takes a snapshot of existing data in Postgres and copies it to ClickHouse; Through Parallel Snapshotting, you can expect signficantly faster initial loads. We've seen TBs get moved in hours vs days.
Change Data Capture (CDC): Once the initial load is completed, PeerDB constantly reads changes in Postgres through the logical replication slot and replicates those changes to ClickHouse.
Looking at the below metrics available in PeerDB UI, PeerDB replicated 35000 rows every 13 seconds, maintaining an ingestion throughput of ~2500 rows per second with a latency/data freshness close to 10 seconds on ClickHouse.
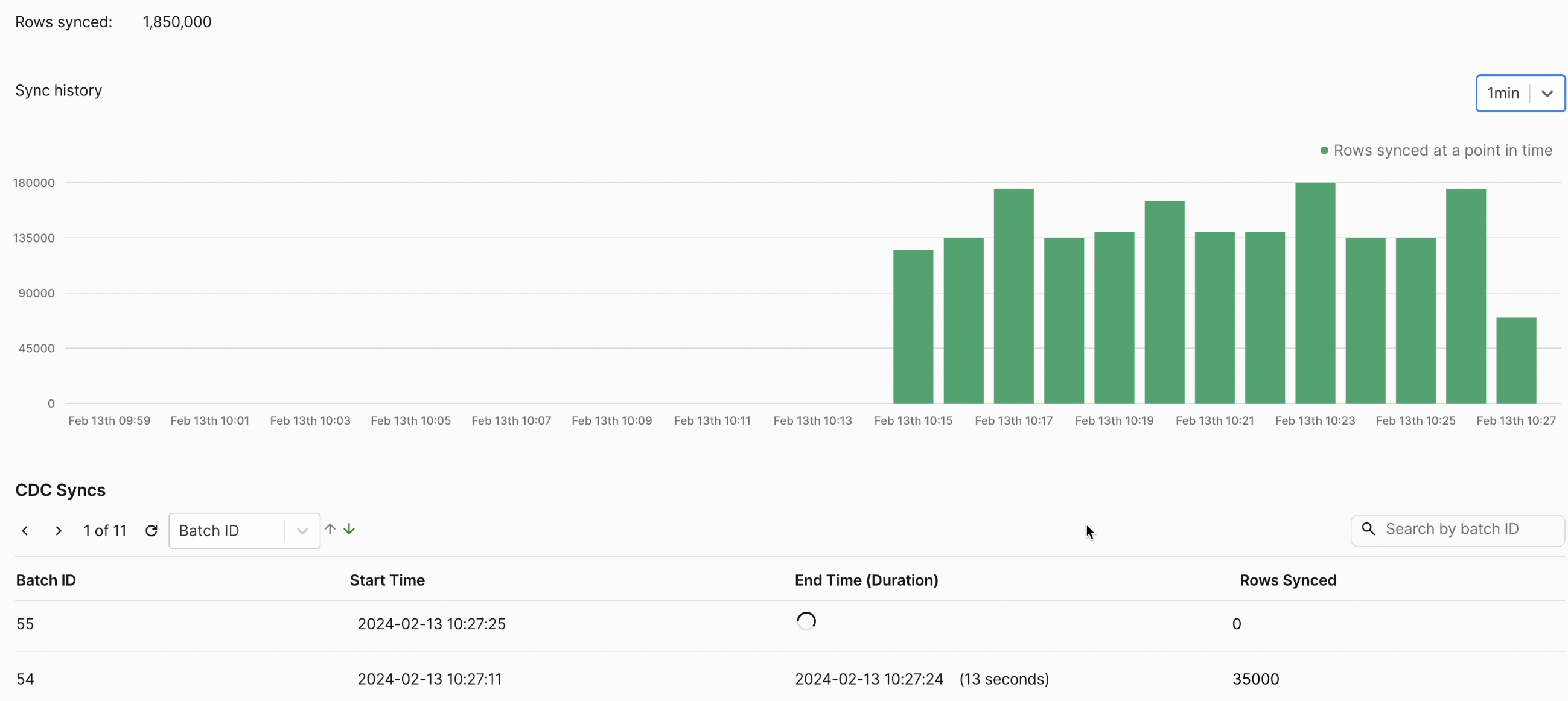
Below is the full demo of PeerDB's MIRROR replicating data from Postgres to ClickHouse
Below section captures a few design choices we made while building the ClickHouse connector.
The final tables that are created automatically created by PeerDB in ClickHouse are of the type ReplacingMergeTree. Both INSERTs and UPDATEs in Change Data Capture (CDC) are captured as new rows with different versions (using _peerdb_version) in ClickHouse. The ReplacingMergeTree query engine takes care of periodic deduplication using the PRIMARY KEY column. DELETEs from PostgreSQL are propagated as new rows that are marked as deleted (using the _peerdb_is_deleted column). The snippet below shows the target table definition for the goals table in ClickHouse.
clickhouse-cloud :) SHOW CREATE TABLE public_goals;
CREATE TABLE peerdb.public_goals
(
`id` Int64,
`owned_user_id` String,
`goal_title` String,
`goal_data` String,
`enabled` Bool,
`ts` DateTime64(6),
`_peerdb_synced_at` DateTime64(9) DEFAULT now(),
`_peerdb_is_deleted` Int8,
`_peerdb_version` Int64
)
ENGINE = SharedReplacingMergeTree
('/clickhouse/tables/{uuid}/{shard}', '{replica}', _peerdb_version)
PRIMARY KEY id
ORDER BY id
SETTINGS index_granularity = 8192
PeerDB aims to map data types from PostgreSQL to their native counterparts in ClickHouse. All numeric, string, and date types are mapped to corresponding data types in ClickHouse. More advanced data types, such as ARRAYS, are mapped to the Array type in ClickHouse. As of now JSON, JSONB and HSTORE are mapped to String on ClickHouse. For more detailed information on Data Type Mapping, you can check our GitHub repo. We will be improving Data Type support further in the near future.
Raw CDC changes from PostgreSQL are staged in S3 in the form of Avro files. PeerDB OSS requires users to specify an S3 stage when creating the ClickHouse Peer. In PeerDB Cloud, we manage it for you.
We hope you enjoyed reading the blog. If you're a ClickHouse user and wish to replicate data from Postgres to ClickHouse using PeerDB, please check out the links below or reach out to us directly!